在 [精進魔法] Optimization:優化深度學習模型的技巧(上)一文中提及了下面三種優化 deep learning 模型的作法:
接下來想先跟各位見習魔法使探討「學習率(Learning Rate)」這個參數,Learning Rate 掌握模型的學習進度,如何調整學習率是訓練出好模型的關鍵要素。
該圖為學習率對梯度下降的影響,如果學習率太小,代表對神經網絡進行非常小的權重更新,會使其訓練變非常緩慢;然後學習率太大,可能導致無法收斂。
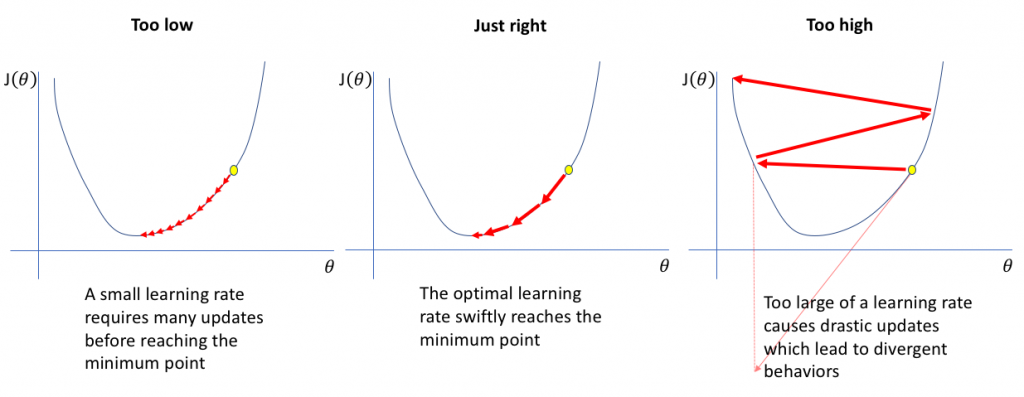
下圖顯示若學習率進一步提高將導致損失增加,這是因為損失反彈甚至偏離最小值的狀況: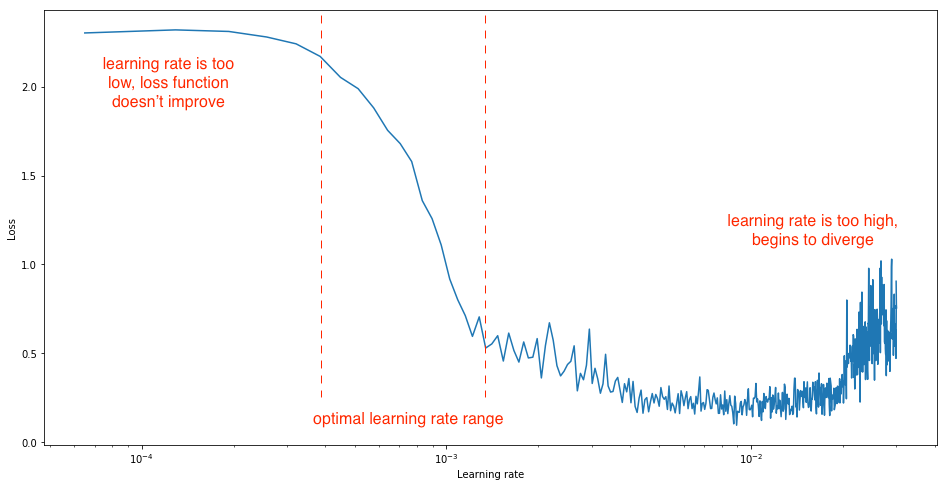
圖片來源:https://www.jeremyjordan.me/nn-learning-rate/
因此如何找到最佳學習率是很重要的議題,加上之前提過的 Gradient Descent 擁有學習率是固定的缺點,所以這邊主要介紹自適應學習率的演算法: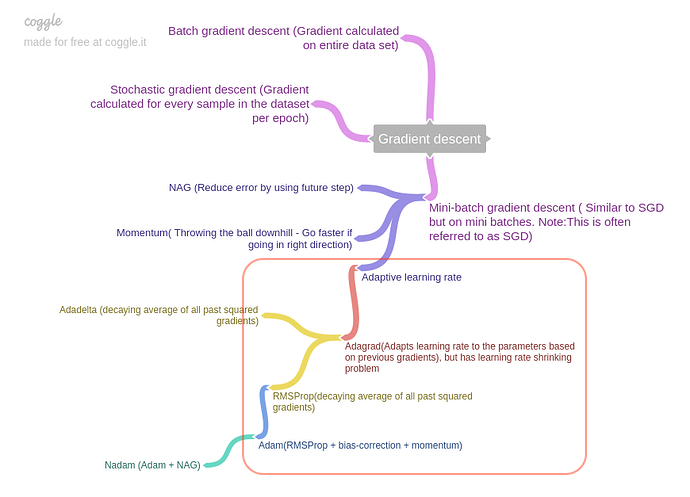
圖片來源:https://forums.fast.ai/t/how-do-we-decide-the-optimizer-used-for-training/1829/5
AdaGrad:
Adagrad 針對每個參數客制化的值,對學習率進行約束,依照梯度去調整學習率。優點是能加快訓練速度,在前期梯度較小時(較平坦)能夠放大梯度,後期梯度較大時(陡峭)能約束梯度,但缺點是在訓練中後段時有可能梯度趨近於 0,而過早结束學習過程。
RMSProp:
Geoff Hinton 所提出,可改善 AdaGrad 的缺點。RMSProp 比 AdaGrad 多了一個衰減系統,它會聯繫之前的每一次梯度變化情況來更新學習率,緩解 Adagrad 學習率下降過快的問題。
Adam:
是實務上常用的方法,直覺來說 Adam 是 AdaGrad 跟 momentum 的融合,優點主要在於它有做偏置校正,使每次迭代學習率都有個確定範圍,讓參數的更新較為平穩。
下圖為國外研究者使用大型模型和數據集來證明 Adam 可以有效地解決實際的深度學習問題: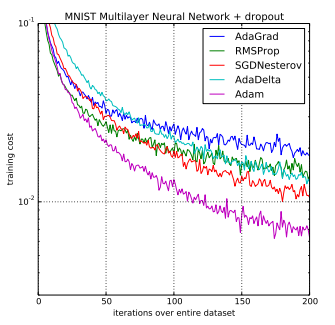
圖片來源:https://machinelearningmastery.com/adam-optimization-algorithm-for-deep-learning/
為了讓大家先對 Optimizer 有認識,所以這裡不貼上數學式來嚇人,有興趣的人可以再額外去研究,推薦這個參考資源,作者有在持續更新最新的 Optimization Algorithms:http://ruder.io/optimizing-gradient-descent/
原本想在這篇把所有想說的 Optimization 講完,但上班族很累 der,所以這系列還會有一篇喔,為大家獻上美好的祝福。

《為美好的世界獻上祝福!》惠惠的 Explosion!
我覺得 adam 是 rmsprop 與 momentum 的組合、如果從參數去看,也能看到 rmsprop 的 alpha 影子。
我覺得 adam 是 rmsprop 與 momentum 的組合、如果從參數去看,也能看到 rmsprop 的 alpha 影子。

